AI Use vs AI Output - Provn AI Career Hub
Using AI a lot doesn’t mean you’re doing useful work with it. What counts is what actually ships: artifacts, cycle time, quality, and business relevance.
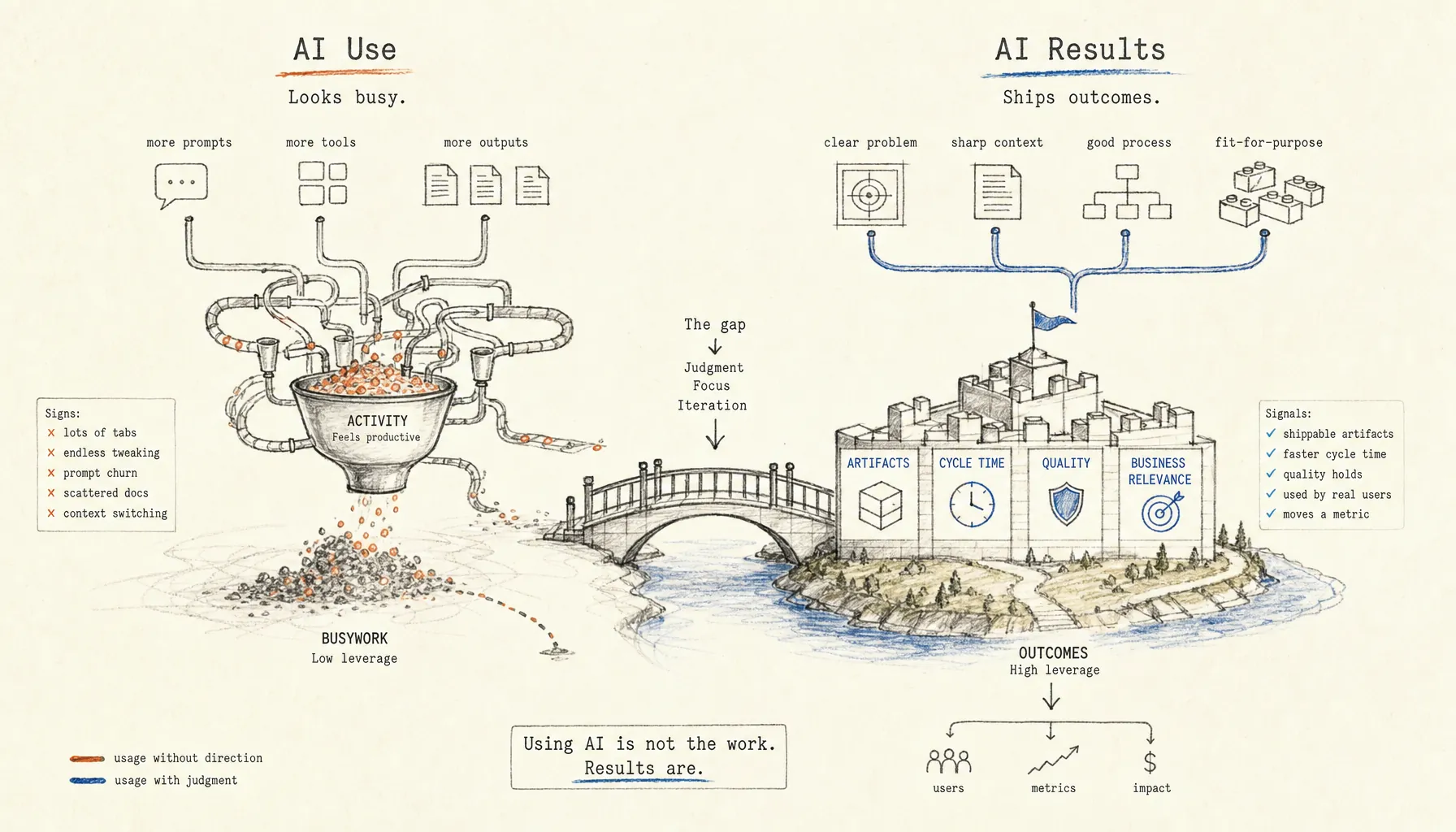
AI Use vs AI Output: How to Tell Who Is Actually Productive
Microsoft reported in 2024 that 75% of global knowledge workers were using AI at work. That number sounds impressive until you ask the obvious follow-up: did the work actually get better? That’s the real difference in AI use vs AI output. One is tool activity. The other is useful work shipped faster, with better judgment and a result somebody can point to.
This matters for hiring and management in 2026 because “AI fluency” is cheap now. Anyone can say they use ChatGPT. Proof takes a little more effort. Provn’s view is straightforward: performance over pedigree, proof over polish.
Key Takeaways
- AI usage volume measures activity. AI output measures shipped work, quality, speed, and relevance.
- A strong AI-assisted work sample should show the artifact, the before-and-after cycle time, the human decisions, and the business result.
- Managers should not reward prompt counts, tool logins, or piles of AI-generated material that nobody reviewed.
- The best candidates can explain where AI helped, where it failed, and what judgment they applied.
- Output metrics should include shipped artifacts, cycle time, defect rate, adoption, and revenue or cost impact.
AI Use vs AI Output: The Useful Distinction
AI use vs AI output comes down to one thing: are you measuring tool activity or completed work? AI use asks how often someone opens ChatGPT, Claude, Copilot, or an internal agent. AI output asks what actually got shipped because of it.
That sounds like a small distinction. It isn’t. A candidate can spend four hours generating drafts and still produce nothing worth reviewing. A product manager can run twenty research summaries and still miss the decision. A developer can lean on an AI coding assistant all day and still make review worse if the code is brittle.
According to Microsoft’s 2024 Work Trend Index, 78% of AI users were bringing their own AI tools to work. That tells us adoption moved faster than governance. It does not tell us whether the work improved.
The same thing shows up in hiring. “I use AI daily” is a weak signal now. “I cut a customer reporting workflow from six hours to 45 minutes, reduced manual errors, and documented the review process” is a strong one. One is behavior. The other is proof.
Why AI Tool Usage Is a Weak Productivity Signal
AI tool usage is easy to inflate because it measures motion, not judgment. High usage can mean skill. It can also mean rework, confusion, sloppy prompting, or an agent stuck in a loop while everyone pretends that counts as productivity.
That’s the trap in a lot of 2026 management dashboards. Tool logins are visible. Prompt counts are visible. Token consumption is visible. Real work is messier. You see it in shipped product changes, closed tickets, cleaner documentation, better sales follow-up, shorter analysis cycles, and fewer defects.
The research is more grounded than the usual hype. In a field study of customer support agents, Brynjolfsson, Li, and Raymond found that access to generative AI increased resolved chats per hour by 13.8% on average, with larger gains for less experienced workers. That is output measurement: resolved chats per hour, not “number of AI prompts submitted.”
There is a cost side too. Usage volume turns into waste when teams automate first and think later. For the broader economics, see Provn’s pillar on AI cost vs employees. The narrower point here is simple: if usage rises and output does not, the company bought activity.
AI Output Metrics: Shipped Artifacts, Cycle Time, Quality, and Business Relevance
AI output should be judged across four measures: shipped artifacts, cycle time, quality, and business relevance. That’s how you separate actual builders from people who are just very busy inside a chatbot window.
A useful artifact is something another person can inspect, use, deploy, test, or make a decision from. A slide deck can count. So can code, a customer segmentation model, a support macro library, a pricing analysis, a design prototype, or a documented operating procedure. The artifact has to survive contact with real work. That’s the standard.
| Metric | Weak signal | Strong signal |
|---|---|---|
| Shipped artifacts | “Generated 40 campaign ideas.” | “Shipped 3 tested campaigns; one produced 18% lower cost per qualified lead.” |
| Cycle time | “Used AI to work faster.” | “Reduced first-draft analysis time from 2 days to 4 hours, with review unchanged.” |
| Quality | “AI wrote the code.” | “Maintained test coverage, passed review, and reduced escaped defects.” |
| Business relevance | “Built an AI workflow.” | “Saved 12 analyst hours per week on a recurring finance process.” |
Quality is the part people skip. According to Google Cloud’s 2024 DORA report, AI adoption in software work had mixed relationships with delivery outcomes, including tradeoffs teams had to manage rather than automatic gains. That lines up with what a lot of operators already know from experience: AI can speed up creation while dumping more work into review.
The best output metric is not a single number. It’s a chain: the artifact shipped, cycle time changed, quality held or improved, and the work mattered to the business.
How Candidates Can Prove AI Output in a Portfolio
Candidates prove AI output by showing the work product and the judgment behind it. A portfolio that just lists tools used reads like software inventory, not evidence of ability.
The strongest AI portfolios look more like case files. They show the starting problem, the constraints, the artifact, the workflow, the human decisions, and the result. This is where builders separate themselves from prompt tourists.
- Choose one real project where AI changed the speed, scope, or quality of the work.
- Show the shipped artifact, such as code, analysis, prototype, workflow, memo, dashboard, or operating procedure.
- Document the baseline process, including the old cycle time, manual steps, error points, or cost.
- Explain where AI was used and where human review changed the output.
- Quantify the result with time saved, defects reduced, revenue influenced, adoption, or decision speed.
- Include one failure or correction that shows judgment rather than blind trust in the tool.
That last step matters. AI judgment is becoming a real hiring signal because these tools produce plausible work fast. Provn gets into that in more detail in AI Judgment at Work: Examples and Evaluation Criteria and AI Skills in Hiring (2026): Portfolio Proof and Interview Signals.
A good candidate does not say, “AI helped me write faster.” They say, “The model misclassified enterprise churn drivers as pricing issues. I checked against renewal notes, rebuilt the taxonomy, and the final dashboard changed the customer success team’s renewal playbook.” That is output. That is judgment.
How Managers Should Evaluate AI-Assisted Work Without Rewarding Noise
Managers should evaluate AI-assisted work by looking at outcomes, not enthusiasm. The right question is not who uses AI the most. It’s who ships better work with less waste.
A practical review system has three layers. First, artifact review: what changed in the product, process, customer experience, or decision quality? Second, process review: did AI reduce cycle time, or did it just move work into cleanup? Third, risk review: did the person catch hallucinations, privacy issues, weak assumptions, or brittle automation?
According to Stanford HAI’s 2025 AI Index Report, reported organizational AI use rose sharply in 2024. Adoption at that scale creates a measurement problem. Teams need evidence that AI work is productive, safe, and worth the spend.
This matters even more for agentic workflows. Agents can consume tokens, call tools, retry tasks, and generate long traces without producing anything useful. For cost mechanics, see Agentic AI Costs (2026): Token Usage and Workflow Controls and AI Token Costs (2026): Pricing Forecasts and Budget Controls. For evaluation, the manager’s job is simpler and colder: what artifact came out of the run, and who reviewed it?
Teams that skip this usually confuse automation with delegation. That failure pattern sits behind a lot of bad replacement plans. Provn covers the organizational side in AI Replacing Employees (2026): Hidden Costs and Rehiring Signals.
AI Use vs AI Output Scorecard
A simple scorecard turns AI output from a vague claim into something you can actually review. The scorecard should weigh shipped work more heavily than tool activity.
Use this in interviews, performance reviews, or project retrospectives. It is intentionally plain. If someone cannot explain their AI-assisted work in these terms, the work probably is not mature enough to trust.
| Category | Question | Evidence to request |
|---|---|---|
| Artifact | What was shipped? | Link, demo, repo, memo, dashboard, workflow, or customer-facing asset. |
| Cycle time | What got faster? | Before-and-after time, throughput, queue reduction, or delivery date impact. |
| Quality | What stayed accurate or improved? | Tests, review notes, defect rates, customer feedback, or QA outcomes. |
| Judgment | Where did the human override AI? | Rejected outputs, corrected assumptions, risk checks, or escalation notes. |
| Business relevance | Why did the work matter? | Revenue, cost savings, adoption, decision speed, retention, or operational hours saved. |
The scorecard also keeps hiring honest. A credential-heavy candidate may talk fluently about tools and still have no shipped proof. A builder may have a less polished resume but a much stronger chain of artifacts. That is the market Provn is built for: people who can show the work.
For related measurement models, see AI Productivity vs Usage: Output Metrics and ROI Signals. For candidates trying to package this proof into a hiring narrative, see AI Builder Jobs (2026): Portfolio Proof and Team Scale.
Frequently Asked Questions
What is the difference between AI use and AI output?
AI use measures how often someone uses AI tools. AI output measures what they ship because of those tools, including artifacts, cycle time improvements, quality, and business relevance. The second measure is more useful for hiring and management because it connects AI activity to work that can actually be inspected.
How do you measure AI output at work?
Measure AI output by reviewing shipped artifacts, before-and-after cycle time, quality signals, and business impact. Strong evidence includes deployed code, approved analysis, usable workflows, test results, adoption data, revenue influenced, cost saved, or hours removed from a recurring process.
Is frequent AI use a good hiring signal?
Frequent AI use is a weak hiring signal by itself. It becomes meaningful only when paired with proof: a portfolio artifact, an explanation of the workflow, evidence of human judgment, and a measurable result. Hiring teams should ask candidates to show the work, not just name the tools.
What is a good example of meaningful AI output?
A good example is a support operations project that cuts ticket triage time from 10 minutes to 2 minutes per case while maintaining QA accuracy. Useful proof would include the workflow, review rules, baseline timing, post-launch timing, and defect checks.
Why do managers confuse AI usage with productivity?
Managers confuse AI usage with productivity because usage data is easier to capture than quality. Tool logins, prompt counts, and token volume show up neatly in dashboards. Business value requires someone to review artifacts, customer outcomes, cycle time, and error rates, which is harder and less tidy.