Managing AI Agents at Work: Builder Skill Guide
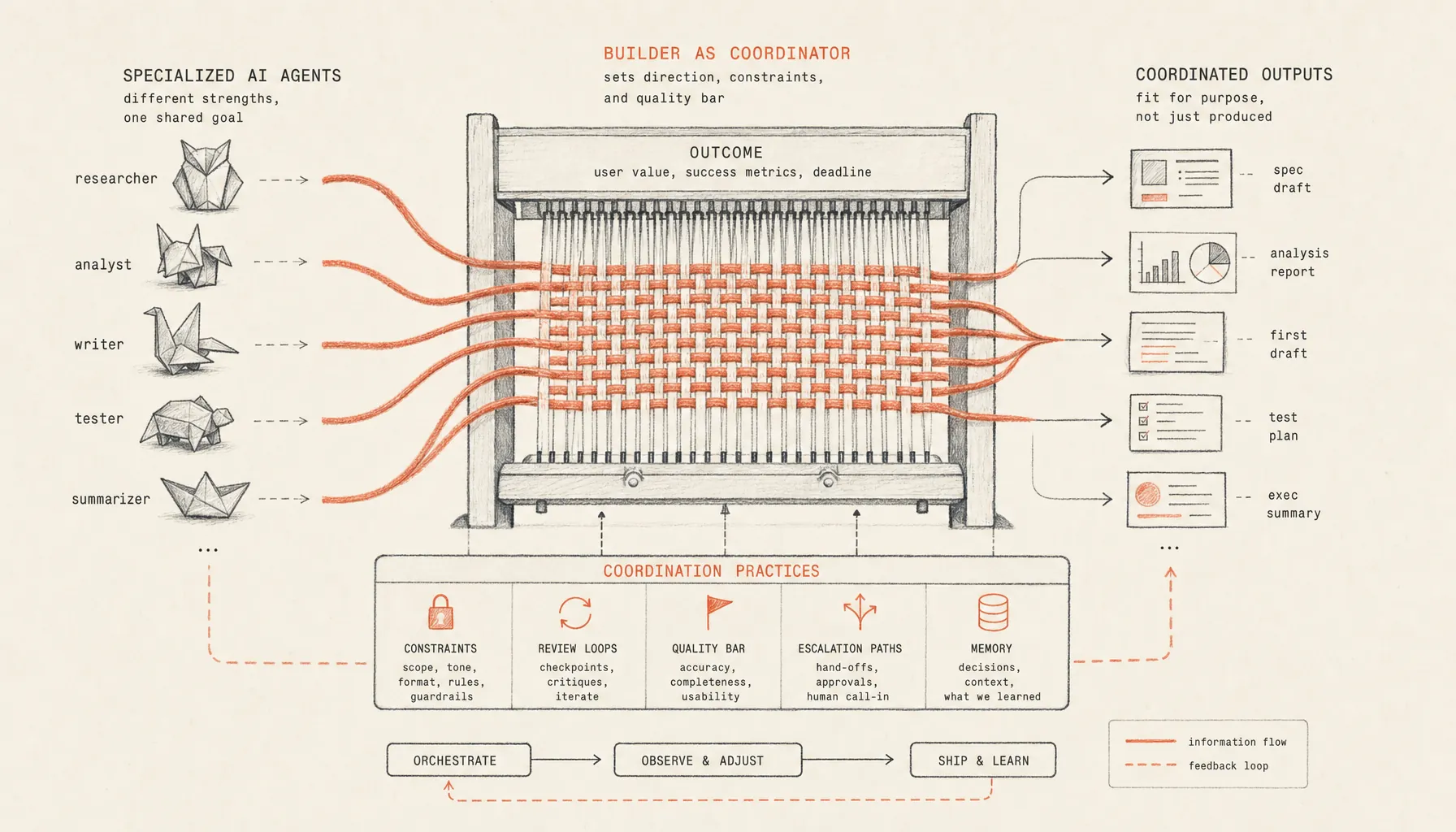
Managing AI agents at work is quickly becoming a basic coordination skill: builders set clear outcomes, constraints, review loops, and escalation paths instead of treating AI like a single tool.
Microsoft reported in its 2024 Work Trend Index that 75% of global knowledge workers were already using AI at work, even though most companies still had no clear rules for how agents should operate.
That mismatch is exactly why managing AI agents has become an early coordination skill. The builder who can direct agentic systems, inspect their work, set limits, and close the loop on errors is doing something much closer to running a small system than using a shiny new tool.
Key Takeaways
- Managing AI agents at work means defining outcomes, constraints, tools, review points, and escalation rules for systems that can take multi-step actions.
- The core skill is coordination. Builders need to break work apart, assign responsibility, check outputs, and decide when human judgment should override automation.
- Agentic workflows need explicit feedback loops because Anthropic’s guidance on building effective agents is clear: more autonomy brings more cost, more latency, and more ways to fail.
- Good proof lives in artifacts: task plans, eval rubrics, failed runs, corrections, logs, before-and-after outputs, and short notes on judgment calls.
- Companies hiring builders read agent management as a sign of operating maturity because it shows how someone handles ambiguity, review, risk, and delivery.
What does managing AI agents at work actually mean?
Managing AI agents at work means directing systems that can plan, use tools, make intermediate decisions, and produce work across multiple steps inside human-set boundaries. The job is to define the outcome, control the limits, inspect intermediate outputs, and decide when the agent should keep going, stop, or hand work back.
The word “agent” gets thrown around a little too loosely right now. In practice, the difference is action. A chatbot answers. An agent moves through a sequence: read this database, draft this analysis, compare it with prior examples, file a ticket, generate a test case, or ask for approval before sending. That extra movement creates value. It also creates more ways for things to go sideways.
The old tool model was simple. Open the software. Do the task. Save the file. Agentic work adds a control layer. The builder becomes the one setting intent, scope, guardrails, and review criteria. That is why this skill looks managerial before it looks technical.
It also matters in hiring. A builder who says “I used AI” is not telling a company much. A builder who can show how they assigned work to an agent, caught a bad assumption, rewrote the prompt, added a validation step, and shipped the final output is giving real evidence. For a broader view of how that plays in early hiring, see How to Get Hired as an Early-Career Builder in 2026: Proof, Requirements, Timeline, and Process.
Why does agentic work look more like coordination than tool use?
Agentic work looks like coordination because the builder is no longer just producing output. The builder is assigning work, sequencing steps, setting standards, watching for drift, and correcting it when it shows up.
The analogy that usually makes this click is a production floor, not a calculator. A calculator waits. A production floor has stations, handoffs, quality checks, and failure points. One station can be fast and wrong. Another can be accurate and slow. Whoever runs the system owns both throughput and defects.
Anthropic separates workflows from agents: workflows follow predefined paths, while agents direct their own process and tool use. That distinction matters at work. A workflow helps when the path is stable. An agent helps when the path needs judgment, exploration, or adaptation.
The mistake is treating autonomy as the goal. It is not. Autonomy gets expensive fast when the task is simple. It adds latency, token cost, review burden, and fresh failure modes. A builder who uses a full agent loop to rename 40 files is showing bad judgment. A builder who uses agents to research a market, reconcile contradictions, draft scenarios, and surface uncertainty is doing something much closer to real work.
That is the early coordination skill: knowing when to automate, when to constrain, when to review, and when to take the work back yourself.
What skills matter when directing AI agents?
The strongest AI agent management skills are task decomposition, constraint design, context control, evaluation, and escalation judgment. Those five decide whether an agent produces usable work or just polished nonsense.
Most early builders overfocus on prompts. Prompts matter, sure, but they are not the operating system. The operating system is the full loop around the agent: what it can see, what it can do, how success gets measured, what evidence it has to produce, and where a human needs to step in.
| Skill | What it looks like at work | Weak signal | Strong signal |
|---|---|---|---|
| Task decomposition | Breaking a vague outcome into ordered work units | “Research competitors” | “Identify 10 competitors, extract pricing pages, compare onboarding claims, flag missing evidence” |
| Constraint design | Setting boundaries before the agent acts | “Write a plan” | “Use only cited sources from 2024 or later, exclude unverifiable claims, produce assumptions separately” |
| Context control | Giving enough information without flooding the model | Dumping every document into the prompt | Providing source hierarchy, examples, definitions, and known exclusions |
| Evaluation | Checking output against a standard | Accepting fluent answers | Using rubrics, test cases, citations, spot checks, and adversarial review |
| Escalation judgment | Knowing when automation should stop | Letting the agent send or publish | Routing legal, customer, security, or brand-sensitive work to human review |
These are coordination skills with technical edges. They look a lot like what strong project leads already do: define the work, reduce ambiguity, create checks, and prevent silent failure. The difference is speed. Agents can generate a volume of plausible work that blows past normal review capacity.
For early builders, that creates a real hiring signal. The question is no longer whether someone knows an AI tool. Plenty of people do. The question is whether they can run a small agentic workflow without losing the plot. That sits right next to the broader skill set covered in AI-Native New Graduate Skills: Signals, Examples, and Hiring Criteria.
How do you set outcomes, constraints, and feedback loops for AI agents?
A good agent brief defines the outcome, permitted inputs, forbidden actions, review checkpoints, success criteria, and escalation triggers before the agent starts. It turns a vague instruction into an operating contract.
This is where builders separate themselves. Lots of people can ask an agent to “build a sales list” or “analyze churn.” Far fewer can define the boundary conditions that keep the output useful. The agent does not know which tradeoffs the business accepts unless the builder spells them out.
What outcome should the agent optimize for?
The outcome should name the business result, the deliverable, and the decision it supports. “Create a list of target accounts” is weaker than “create a ranked list of 50 Series A to C developer-tool companies for outbound testing, with funding stage, hiring signal, technical buyer, and source link.”
Strong outcomes cut review time because the agent’s work can be judged against a specific use. They also block format theater. A polished spreadsheet with the wrong company set is still wrong. A rough spreadsheet with the right evidence trail can be fixed.
What constraints should limit the agent?
Constraints should cover sources, tools, time, permissions, style, risk, and stopping conditions. That is the difference between delegation and abdication.
Examples:
- Use only first-party company pages, SEC filings, official documentation, or cited industry sources.
- Do not contact external people or send messages without approval.
- Flag uncertain claims instead of filling gaps with invented details.
- Stop after three failed attempts to retrieve source data.
- Return a decision log with assumptions, exclusions, and unresolved questions.
The security reason is straightforward, not theoretical. OWASP’s Top 10 for Large Language Model Applications lists prompt injection, sensitive information disclosure, and excessive agency among the major risks in LLM systems. Those risks show up exactly where agents get tools and permissions.
What feedback loops keep agent work from drifting?
Feedback loops should check the agent at intermediate points, not just at the end. The earlier you catch drift, the cheaper it is to fix.
A practical loop has three checks. First, inspect the plan before execution. Second, inspect a small sample before scaling. Third, inspect the final output against the rubric. This is basically how experienced managers review human work too: align on the plan, check a draft, then judge the deliverable.
And for proof, save the loop. Do not just show the final answer. Show the original instruction, the first pass, the correction, and the final output. That evidence belongs in the kind of work sample described in Proof of Work for Early-Career Builders: Examples, Checklist, and Steps.
What does a good AI agent workflow look like?
A good AI agent workflow starts narrow, validates early, expands only after a sample passes review, and keeps a record of decisions. The whole point is to make failure visible before it gets expensive.
Here is a practical sequence for managing AI agents at work.
- Define the outcome in one sentence, including the decision the work will support.
- List the allowed sources, tools, data, and actions before the agent starts.
- Break the work into stages with a review checkpoint after the first meaningful sample.
- Write a success rubric with accuracy, completeness, source quality, and usability criteria.
- Run a small test task before handing the agent the full workload.
- Inspect the agent’s plan, evidence, and assumptions before approving scale-up.
- Compare the output against known examples, source documents, or test cases.
- Record failed runs, corrections, and final decisions in a short work log.
- Escalate sensitive, external-facing, legal, financial, customer, or security work to a human reviewer.
- Revise the workflow after delivery based on the errors you found in review.
This can look slower than just asking for the answer. It is not, at least not when the work matters. The fastest route to bad output is skipping the sample check and finding out at the end that the agent optimized for the wrong thing.
Real work usually does not fail in big cinematic ways. It fails by drift. The agent uses an outdated source. It treats a marketing claim like a fact. It assumes two terms mean the same thing. It fills a missing field with a plausible guess. A builder managing the workflow plans for those smaller failures because those are the ones that actually show up.
How should builders evaluate AI agent output?
Builders should evaluate AI agent output with evidence checks, task-specific rubrics, adversarial tests, and comparisons against known-good examples. Fluency is not proof of correctness. It never was.
The National Institute of Standards and Technology’s Artificial Intelligence Risk Management Framework puts measurement, monitoring, and governance at the center of AI risk management. In plain English, if a system cannot be checked, it should not be trusted with work that matters.
Evaluation should change with the task. A research agent needs source-quality checks. A coding agent needs tests. A customer-support agent needs policy review. A data agent needs reconciliation against known totals and sample-level inspection.
| Agent task | Primary failure mode | Evaluation method | Human review trigger |
|---|---|---|---|
| Market research | Unsupported claims | Source audit and citation spot check | Missing source, old source, or conflicting evidence |
| Code generation | Passing syntax with flawed logic | Unit tests, edge-case tests, code review | Security, auth, payments, data access |
| Outbound list building | Wrong target profile | Sample review against ICP rubric | Low match rate in first 20 records |
| Document drafting | Confident misstatement | Fact check against source documents | Legal, financial, medical, or policy claims |
| Data cleanup | Silent data loss | Before-and-after row counts and anomaly checks | Unexpected deletion, merge, or transformation |
The hidden skill here is choosing the right evaluation cost. Not every task needs a formal benchmark. Some need a 10-row sample. Some need a test suite. Some need a second model to critique the first pass. Some need a person who actually knows the domain.
The best builders make that choice explicit. They do not say, “The agent seemed right.” They say, “I checked 15 of 100 records, found two source issues, adjusted the retrieval rule, reran the batch, and added a source-date column.” That is how real work sounds.
Where do AI agent risks show up at work?
AI agent risks show up when systems have access to sensitive context, external tools, customer-facing channels, or permission to change data. Risk goes up fast when an agent can act faster than a human can review.
Most companies are not worried that builders use AI. They are worried about unmanaged AI. That distinction matters. McKinsey’s 2024 State of AI survey found that 65% of respondents said their organizations were regularly using generative AI, nearly double the share from the previous survey. Adoption moved faster than discipline in a lot of teams. No surprise there.
Agent risk usually falls into four practical buckets:
- Data exposure: The agent sees or sends information it should not handle.
- Tool misuse: The agent calls the wrong API, edits the wrong record, or takes an action outside the task scope.
- Authority confusion: Humans treat agent output as approved because it arrives in a finished-looking format.
- Review overload: The agent produces more work than the team can inspect properly.
These risks change the builder’s job. A good agent manager does not ask for maximum automation. They ask for appropriate autonomy. Read-only research is different from write access to a CRM. Drafting an email is different from sending it. Suggesting a data correction is different from applying it to production records.
The operating rule is simple: as permissions rise, review standards should rise with them. If an agent only summarizes public documents, the review burden is modest. If it can contact customers, change prices, access personal data, or modify code, the workflow needs tighter gates.
How do hiring managers read AI agent management as proof?
Hiring managers read AI agent management as proof when the builder shows the operating record behind the output. The strongest signal is not the artifact by itself. It is the judgment trail.
Companies hiring builders are drowning in polished applications. AI made it cheap to produce clean resumes, cover letters, and generic portfolios. That creates a sorting problem. The artifact looks finished, but the work behind it is invisible.
Agent management evidence cuts through that because it shows how the builder thinks under ambiguity. A hiring manager can inspect the brief, the constraints, the failed run, the correction, the evaluation rubric, and the final output. That tells them more than a claimed skill ever will.
This is where Provn’s frame matters: performance over pedigree, proof over polish. The system should not overvalue the school name or the famous logo when the work sample gives better evidence. A builder from Cal State Chico who shows a clean agent workflow with disciplined evaluation should be seen right next to a builder from Duke who lists AI tools without proof. The screen is the problem when it cannot tell the difference.
For companies, this is also a practical filter. It helps identify builders who can work in teams where senior people set direction and younger builders run fast, well-scoped experiments. That hiring shape connects to the larger argument in Barbell Hiring Strategy in AI Teams: Fresh Graduates, Veterans, and Mid-Career Pullback.
What should early-career builders practice next?
Early-career builders should practice agent coordination through small, inspectable projects that show planning, constraints, execution, review, and revision. The point is to make the work visible, not just the result.
Start with work that has a clear evaluation path. Good examples include a research agent that builds a cited competitor matrix, a code agent that writes tests before implementation, a CRM cleanup agent that flags duplicates without editing records, or a content QA agent that checks claims against source documents.
Keep the scope narrow. A five-hour project with a strong work log beats a sprawling demo nobody can verify. Every time. The goal is to show how you direct the system. The final artifact matters, but the control layer is the real signal.
A strong practice project includes:
- A one-page agent brief with outcome, scope, tools, constraints, and review triggers.
- A workflow map showing each step and checkpoint.
- A sample run with raw output and corrections.
- An evaluation rubric with pass, fail, and needs-review criteria.
- A short postmortem explaining what failed, what changed, and what you would do with more time.
Put that evidence where hiring managers can inspect it. A portfolio page should show judgment, not decoration. For structure, review Early-Career Builder Portfolio: Evidence, Judgment, and Review Criteria.
Managing AI agents at work is not some narrow technical trick. It is an early version of operating leverage in AI-native teams: define the outcome, coordinate the system, inspect the work, and own the result.
Frequently Asked Questions
What is managing AI agents at work?
Managing AI agents at work means directing AI systems that can perform multi-step tasks with tools, context, and partial autonomy. The builder defines the outcome, sets constraints, reviews intermediate work, checks final output, and decides when human approval is required.
How is managing AI agents different from using AI tools?
Using an AI tool is usually a single interaction: ask, receive, edit. Managing AI agents is a coordination loop: assign work, limit permissions, inspect plans, review samples, evaluate outputs, and adjust the workflow. The second skill looks much more like managing a process than operating software.
What are examples of AI agent management skills for early-career builders?
Examples include writing agent briefs, breaking vague work into stages, designing source rules, setting review checkpoints, creating evaluation rubrics, logging failed runs, and escalating sensitive work. These skills show whether a builder can handle ambiguity and delivery, not just prompt a model.
How can a builder prove they can manage AI agents?
A builder can prove agent management skill by showing the work record: the original brief, constraints, tool permissions, sample outputs, corrections, evaluation checklist, failed attempts, and final result. Companies hiring builders need to see the judgment trail, not just the finished artifact.
Which AI agent risks matter most at work?
The main risks are data exposure, tool misuse, unsupported claims, excessive autonomy, and review overload. Risk rises when an agent has access to sensitive data, external communication channels, customer records, code repositories, or systems that can change production information.